We thank our partners for their support in clinical data and academic research. (Listed in no particular order)
SurgMotion: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
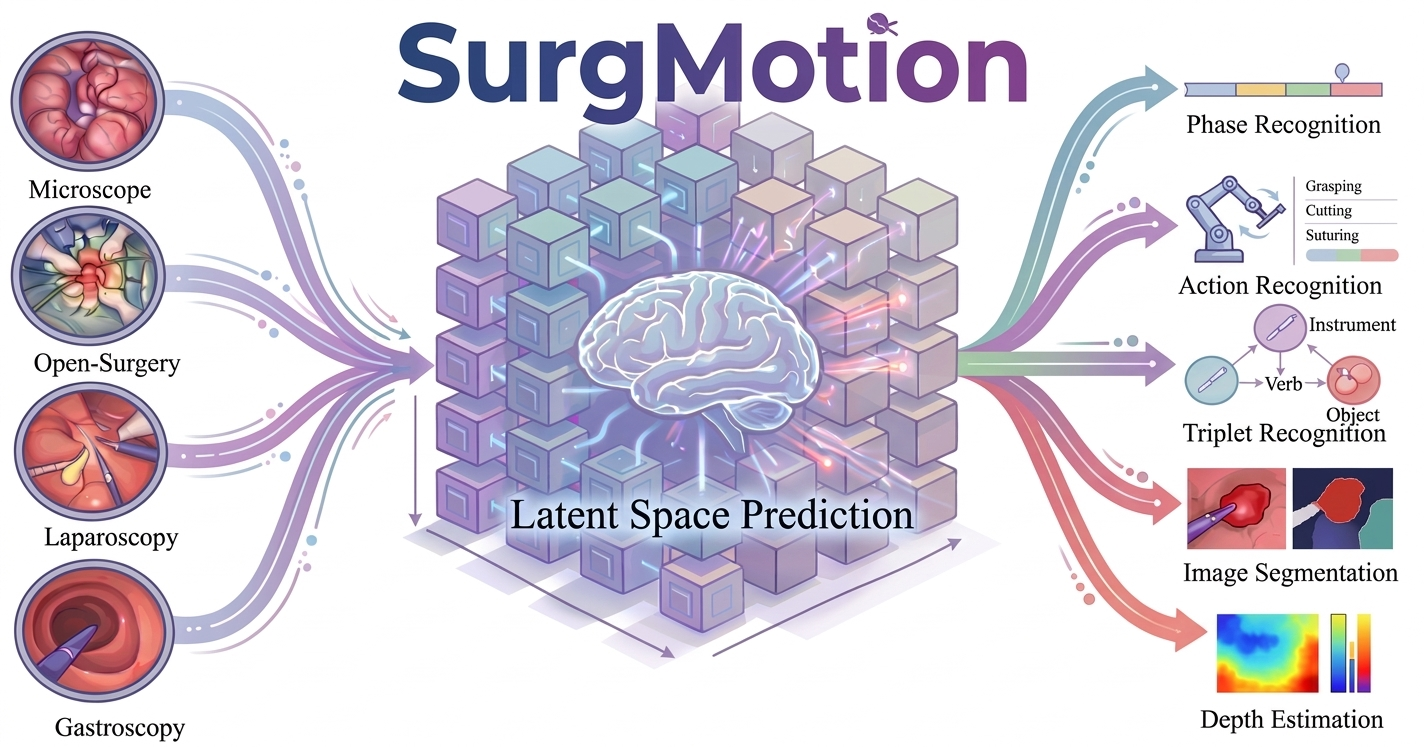
Current surgical foundation models remain trapped in static, image-based paradigms, failing to grasp the complex temporal dynamics essential for surgical understanding. We present SurgMotion, a video-native foundation model that shifts the paradigm from pixel-level reconstruction to latent motion prediction. Built upon the Video Joint Embedding Predictive Architecture (V-JEPA), SurgMotion learns robust spatiotemporal representations without the computational overhead of generative decoding. To unlock its potential, we curate SurgMotion-15M, the largest multi-modal surgical video dataset to date, spanning 13 anatomical regions and 3,658 hours.
We further introduce a Flow-Guided Latent Prediction objective to prevent feature collapse in homogeneous tissues. Extensive experiments demonstrate that SurgMotion outperforms state-of-the-art methods by significant margins: +14.6% F1-score on EgoSurgery and +10.3% F1-score on PitVis. Our work establishes a new standard for data-efficient, motion-aware surgical intelligence.
SurgMotion-15M spans 13+ anatomical regions, creating a diverse landscape for pan-surgical learning.
Frames
Organs
Hours
Tasks
Benchmarks & Visualization
We evaluate SurgMotion on standard laparoscopic benchmarks, cross-domain generalization tasks, and fine-grained action understanding. By leveraging Flow-Guided V-JEPA, our model achieves state-of-the-art performance, recording a +14.6% F1-score improvement on EgoSurgery and +10.3% on PitVis compared to previous methods.
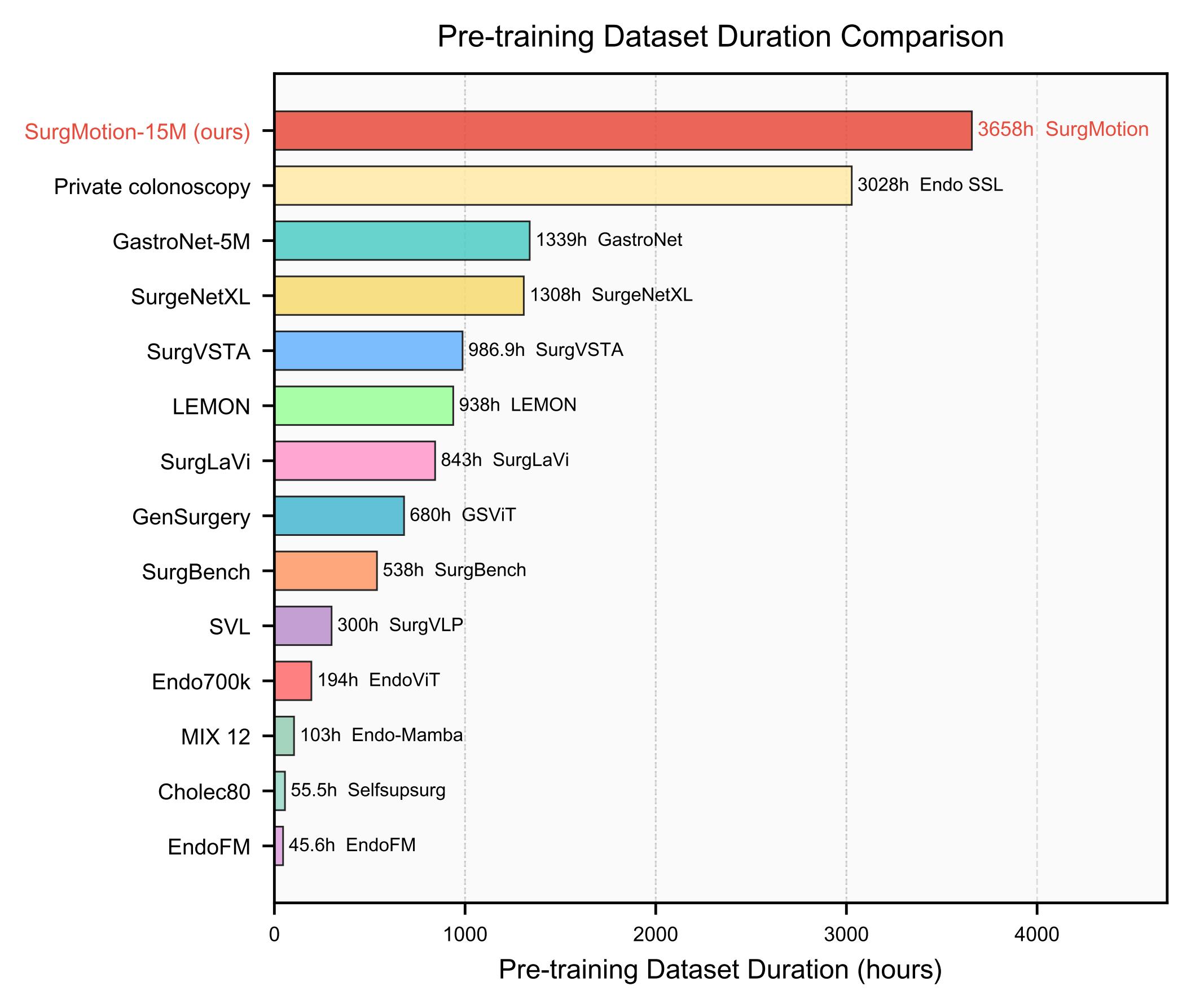
Scaling pre-training data and model capacity together leads to a clear jump in performance. Trained on 3,658 hours of surgical video with 1.01B parameters, SurgMotion sets a new scale for surgical foundation models.
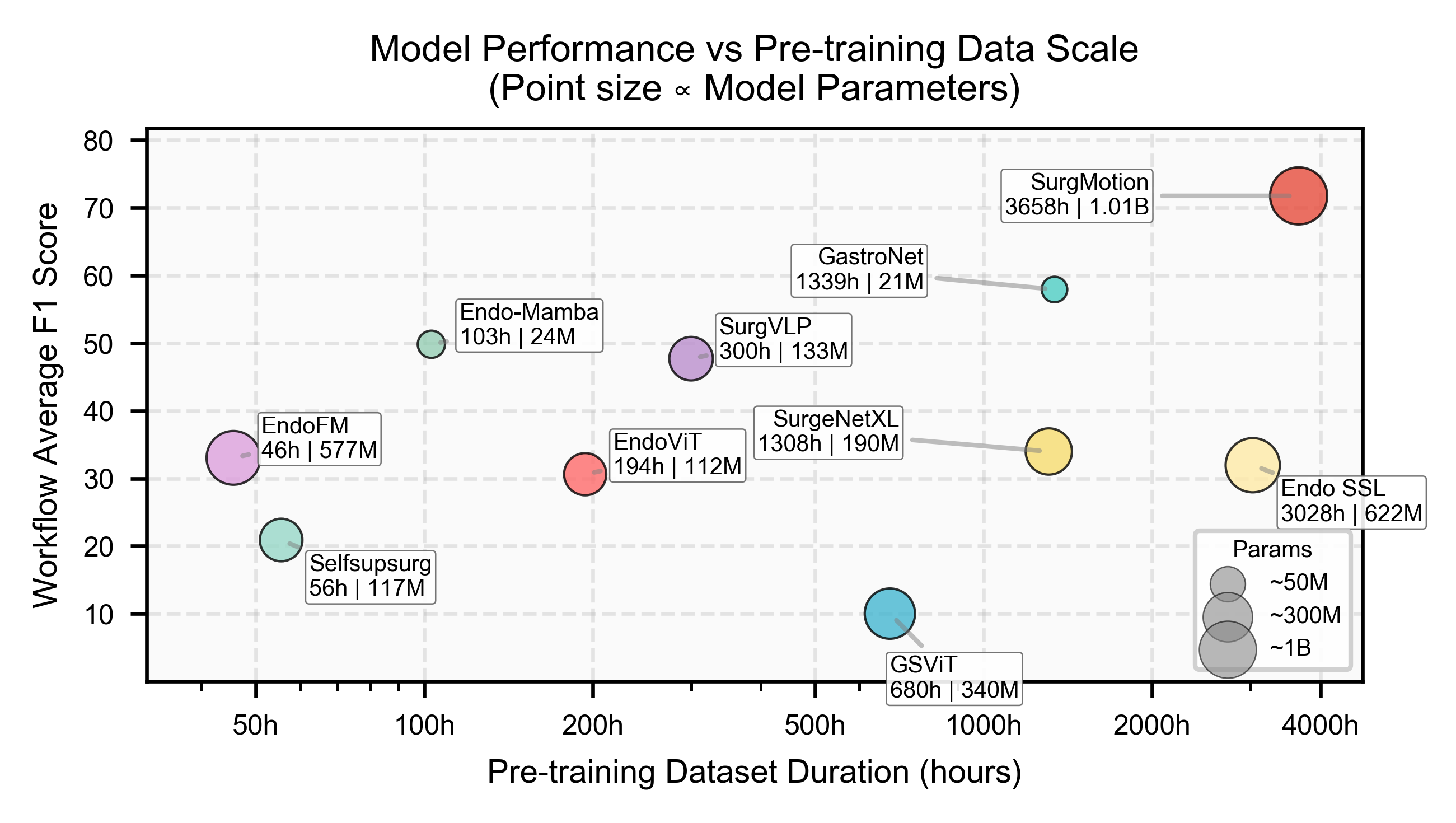
SurgMotion achieves the highest workflow Avg F1 of 72.0 among compared methods, reflecting stronger temporal understanding across surgical workflows.
Across six representative surgical tasks, SurgMotion achieves the best overall results on 5 of 6 tasks, leading in workflow analysis, action recognition, segmentation, triplet recognition, and skill assessment, while remaining competitive on depth estimation.
Doctor Copilot
Beyond benchmarks, SurgMotion powers an agent skill layer for automatic surgical structured analysis, enabling doctor-copilot workflows on real surgical videos.
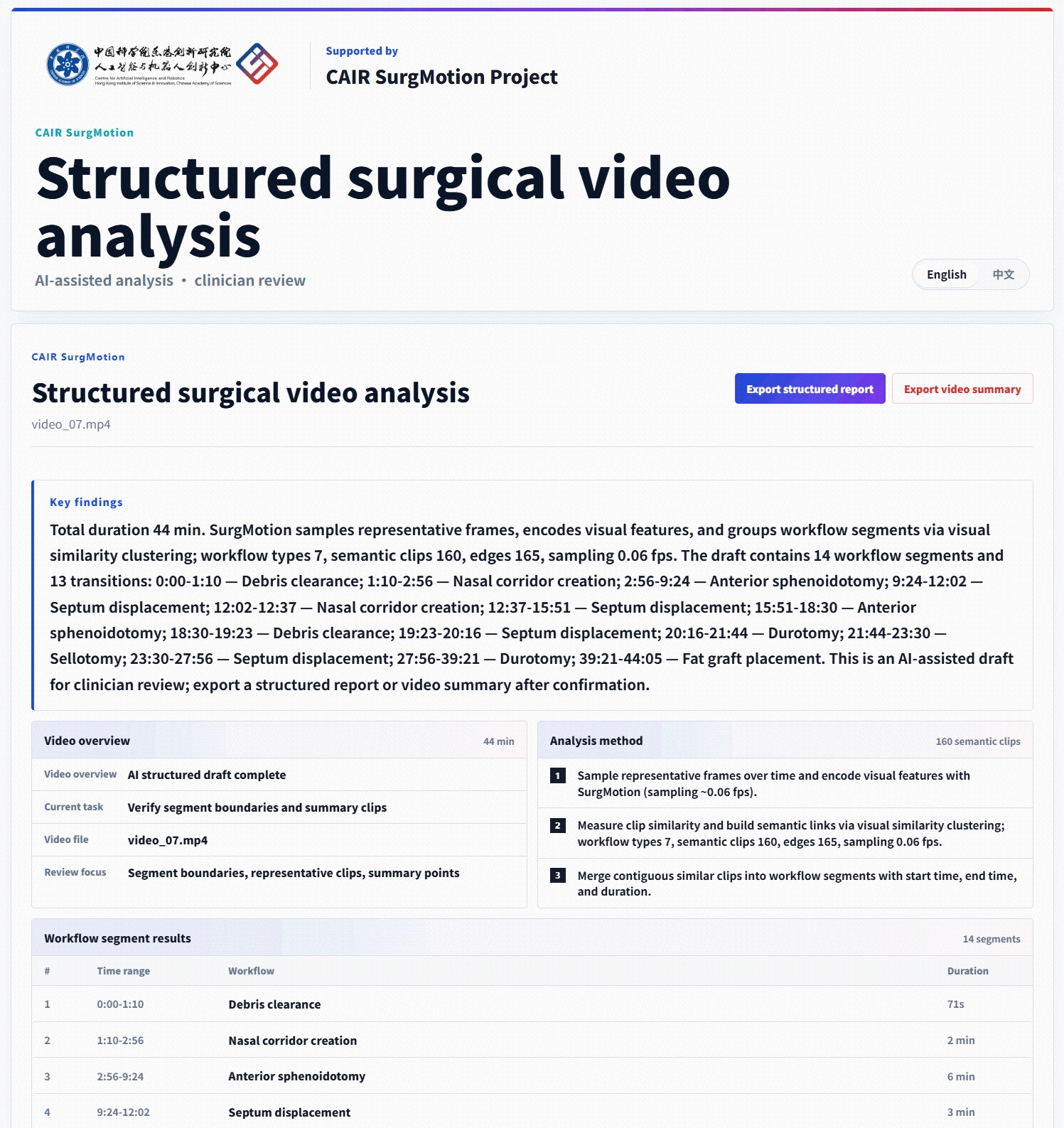
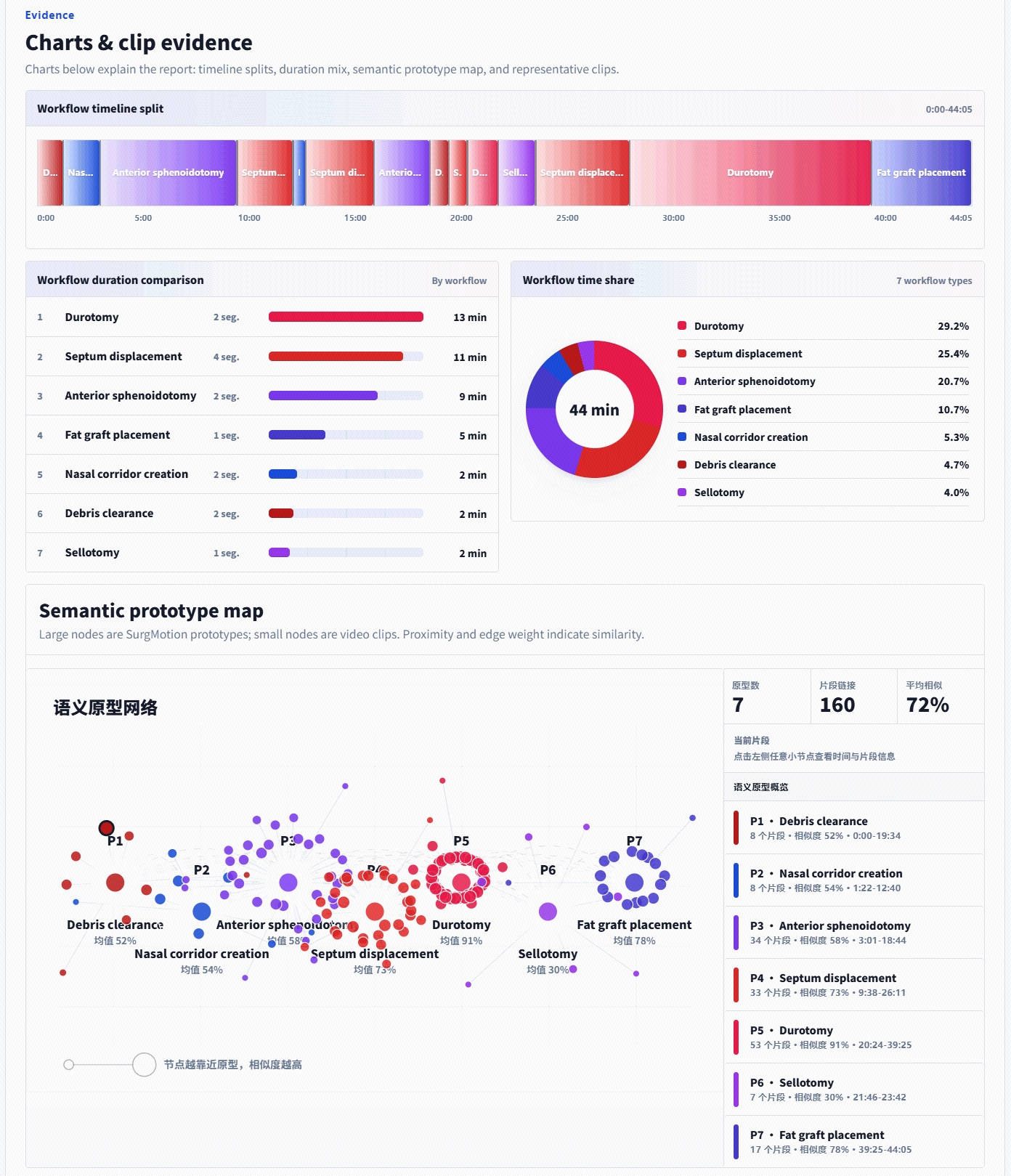
Agent Skill: Automatic Surgical Structured Analysis
Education
In close collaboration with The University of Hong Kong–Shenzhen Hospital, we turn SurgMotion from a research model into a living educational infrastructure—helping surgical knowledge transfer scale beyond one-to-one apprenticeship, and bringing AI-assisted understanding into everyday teacher–doctor training.
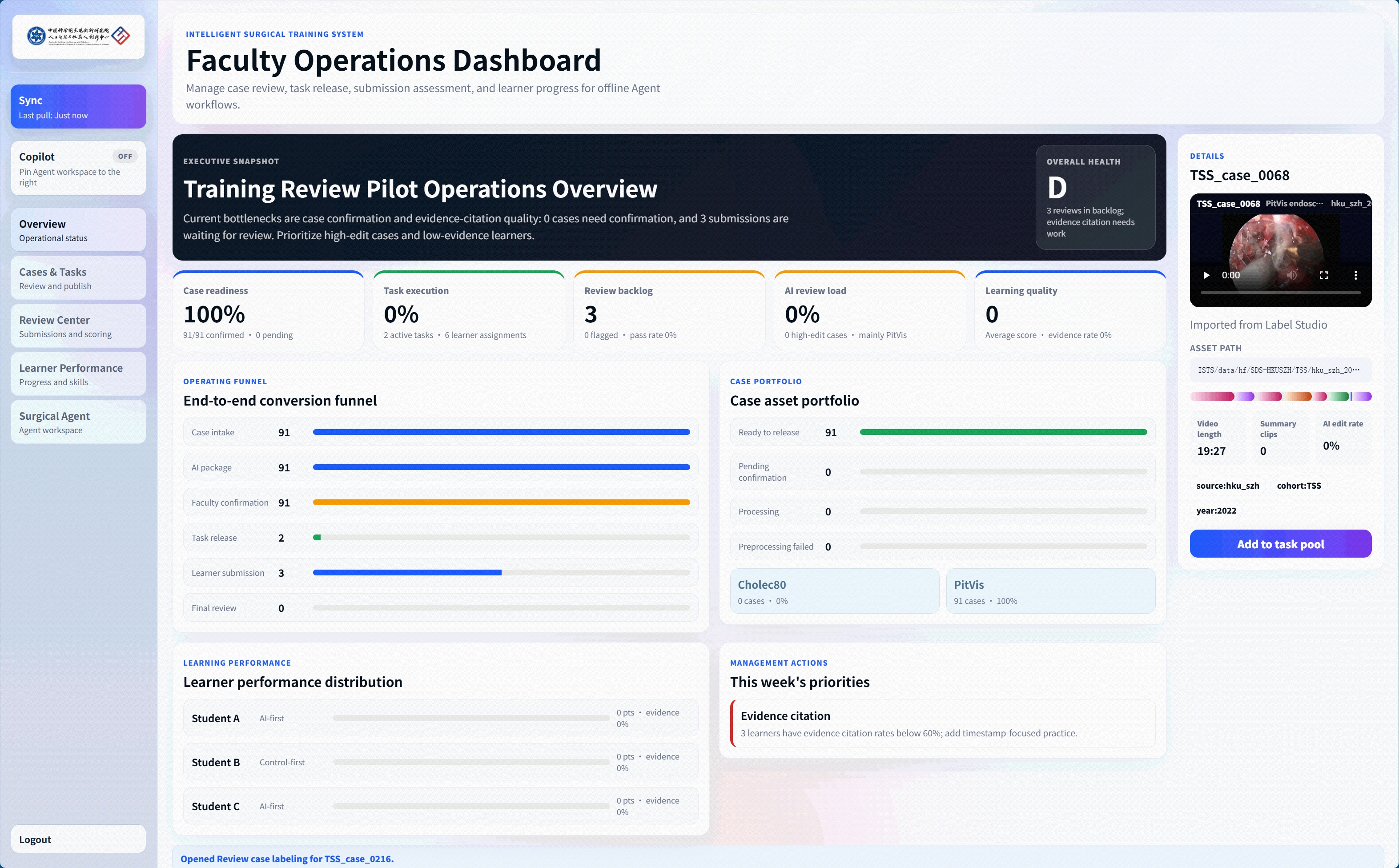
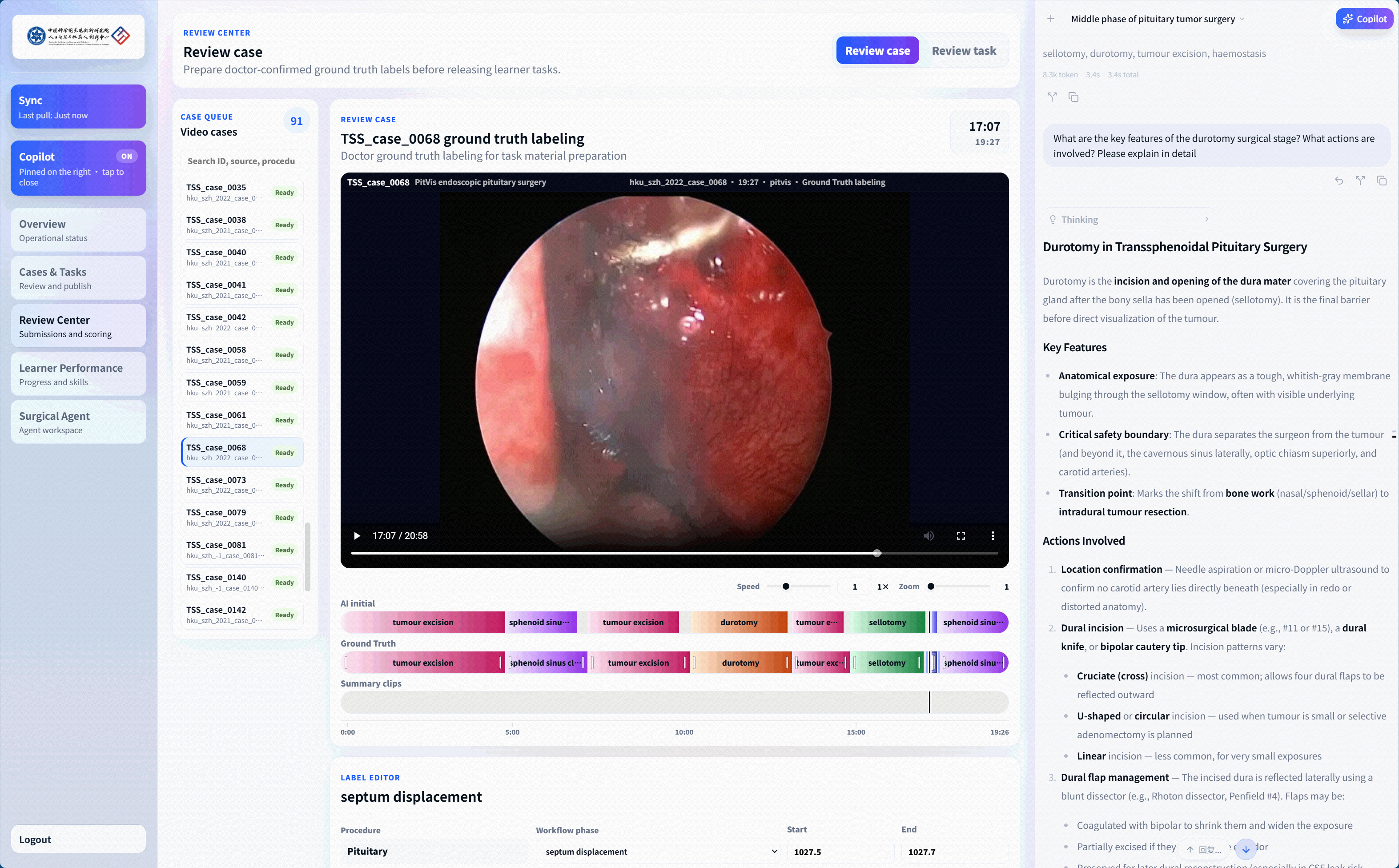
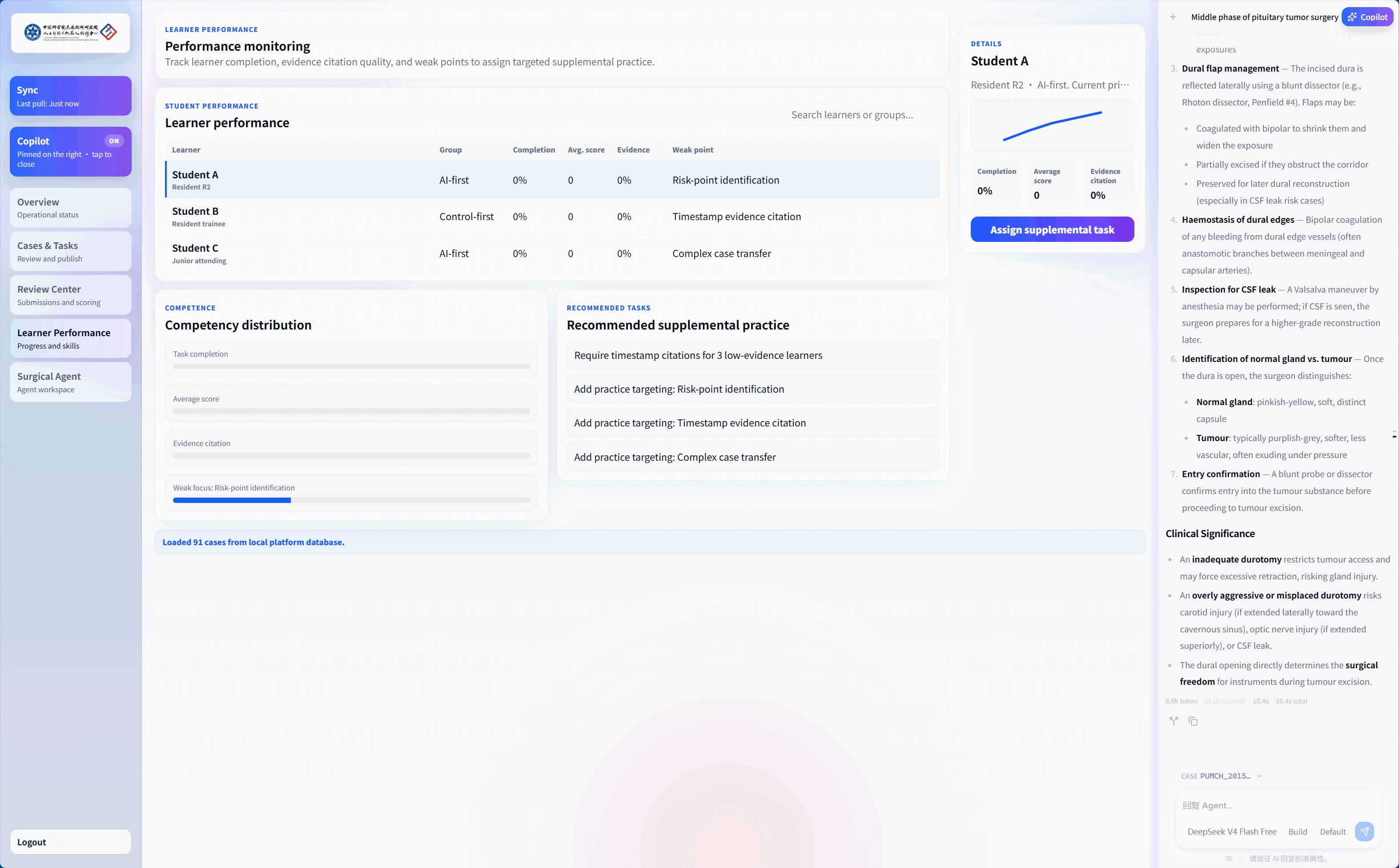
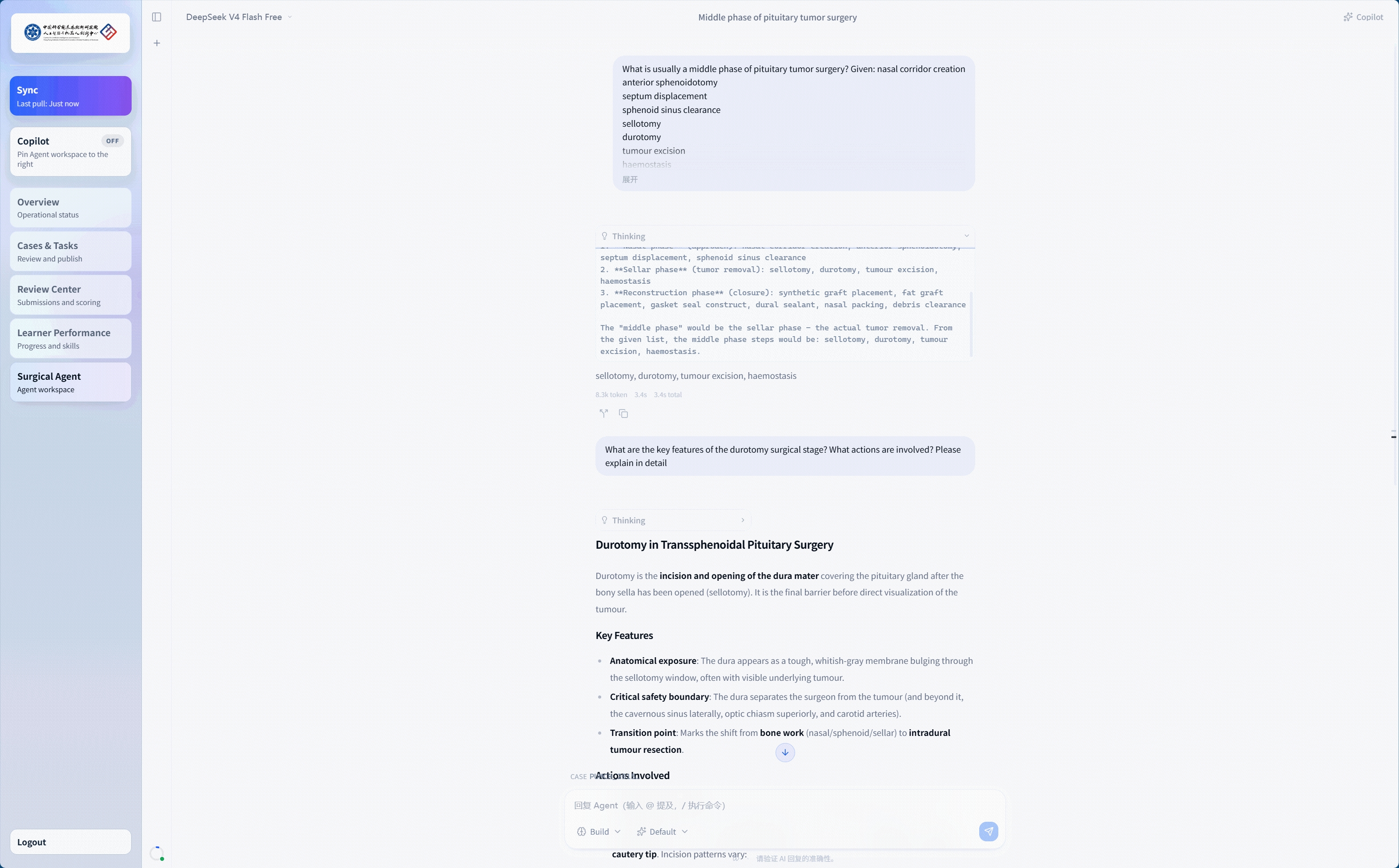
Teacher–Learner Surgical Video Teaching System
If you find this work helpful, you can cite our paper as follows:
@article{SurgMotion2026,
title={SurgMotion: A Video-Native Foundation Model for Universal Understanding of Surgical Videos},
author={Wu, Jinlin and Holm, Felix and Chen, Chuxi and Wang, An and Hu, Yaxin and Ye, Xiaofan and Zang, Zelin and Xu, Miao and Zhou, Lihua and Liao, Huai and Chan, Danny T. M. and Feng, Ming and Poon, Wai S. and Ren, Hongliang and Yi, Dong and Navab, Nassir and Meng, Gaofeng and Luo, Jiebo and Liu, Hongbin and Lei, Zhen},
journal={arXiv preprint},
year={2026}
}We thank our partners for their support in clinical data and academic research. (Listed in no particular order)
Peking Union Medical College Hospital
King's College Hospital
First Affiliated Hospital of SYSU
Prince of Wales Hospital
HKU-Shenzhen Hospital
Technical University of Munich
The Chinese University of Hong Kong